

s01e01: When the Execution Stack Hits the Ceiling
📺 How recursion creates Stack Frames - and when it all explodes

♨ A Lasagna Ricorsiva
Comic ‣ Deep-Dive ‣ Real Failures ‣ Takeaways ‣ Downloads
Cody, bartender at 8 bytes! The Software Restaurant: “I was polishing glasses at the bar, getting ready for the Soft Opening and watched from the side the disaster unfold... Julia, our head chef was following the recipe strictly, because she wanted THE PERFECT DISH, but it all went wrong!
Let’s start from the beginning… It was almost lunch time…”














Steal These Now (Before Going Deep)
For Engineers: Check your recursion depth BEFORE production. One missing if = 3am pager alert. Add unit tests that call your recursive function with n=10,000.
🡆 More for you? Deep Dive section awaits below.
For Tech Leads: When reviewing code, ask: “What’s the maximum depth this can reach?” No answer = no merge. Stack Overflow isn’t a meme, it’s a production killer.
🡆 More for you? Design Review Questions in the middle.
For Managers: When the CTO says “stack overflow from unbounded recursion,” translate: “We forgot the emergency brake. The kitchen spike hit the ceiling because we kept adding tickets with no stop condition.”
🡆 More for you? CEO Recipe near the end.
(Julia’s 1,000-10,000 call limit explains why this matters...)
What Just Happened in Julia’s Kitchen?
Lasagna Ricorsiva looked brilliant - recursive elegance at its finest.
But Julia had a bad Base Case. The ticket spike kept growing... and growing... until it physically hit the ceiling at call 1,247.
Stack Overflow - the smell of exploded kitchen and Julia buried under lasagna sheets.
Welcome to Episode 1 of Season 1 “Memory Management”
8 episodes exploring Stack, Heap, Garbage Collection, Memory Leaks and other hilarious software disasters. New episodes drop bi-weekly:
✅ E01: Stack Overflow & Recursion → You are here
✅ E02: LIFO vs FIFO Starvation → [Read now]
✅ E03: Cache & Stale Data → [Read now]
✅ E04: Heap Fragmentation → [Read now]
✅ E05: Garbage Collection - “Stop the World” → [Read now]
⏳ E06: Memory Leaks (drops Mar 05)
📅 E07: Race Conditions (drops Mar 19)
📅 E08: Deadlocks (drops Apr 02)
Deep Dive: Why did the kitchen actually explode?
The Stack & the Heap
In software engineering, the Stack is the engine of execution. Unlike the Heap, which is a large, messy pool of memory where you have to hunt for space, the Stack is a strictly managed, lightning-fast segment of RAM.
To picture it - from Julia’s perspective the order tickets spike is the Stack and the restaurant’s warehouse is the Heap:

The warehouse is the place you store big objects. It can be very well-organized… or NOT (as you will see in next episodes)! The main issue with the Heap is its accessibility - Ollie has to run all the way down the long corridor to fetch supplies from the warehouse. This travel time is exactly like memory latency - the Heap gives you space, but you pay for it with speed.
The order ticket spike in the kitchen, on the other hand, is a fast-access memory store. The spike is the perfect metaphor for a LIFO (Last-In, First-Out) stack - as you always process the topmost item first.
And what is the Stack Frame?
At the CPU level, the Stack is managed by a special register called the Stack Pointer (SP). Whenever you call a function (poke a new ticket onto the spike), the SP moves to allocate space for a new Stack Frame in the memory (PUSH operation) and whenever the function returns (Julia tears off a ticket) the SP deletes the frame and moves down to older frame (POP operation).

So, practically every Stack Frame is like a single ticket on Julia’s spike created by a table order (a function call). It holds all the local variables of the function. Once the dish is served, the ticket is ripped off and the memory is instantly freed. No leftovers, no mess - unlike the Heap, where things just sit around until someone like the Garbage Collector eventually cleans them up. (Don’t worry, we’ll come to that cleanup crew in next episodes!)
The Call Stack - why code execution uses LIFO?
LIFO stack is incredibly Cache-Friendly. The CPU has tiny, ultra-fast memory caches (L1/L2) right next to it - think of them as Julia's cutting board versus the warehouse. Because Stack data is stored contiguously, it often stays inside these caches, making it thousands of times faster than fetching data from the Heap. All it takes for Julia is to reach out and tear off a ticket.
LIFO is the perfect fit for code flow execution as programs by themselves are practically a set of nested instructions (functions) and the execution context navigates deeply through these functions until they return, before it continue with the “parent” context all the way back to the main() block. In other words - the program is like a lasagna eaten layer after layer at runtime.
Recursion vs. Iteration: How they use the Stack?
There are two ways to build our lasagna - using recursion or using a while loop and in either solution your Base Case is the most critical ingredient. But there is a huge difference on how your code will use the Stack in both scenarios.

A. The Recursive Approach (Nested Stack Frames)
In recursion, every new layer creates a new Stack Frame. The previous frame stays in memory, “waiting” for the top one to finish. Imagine it like if Julia had tickets on the spike for every operation she does. Our code goes like this (dummy Java sample):
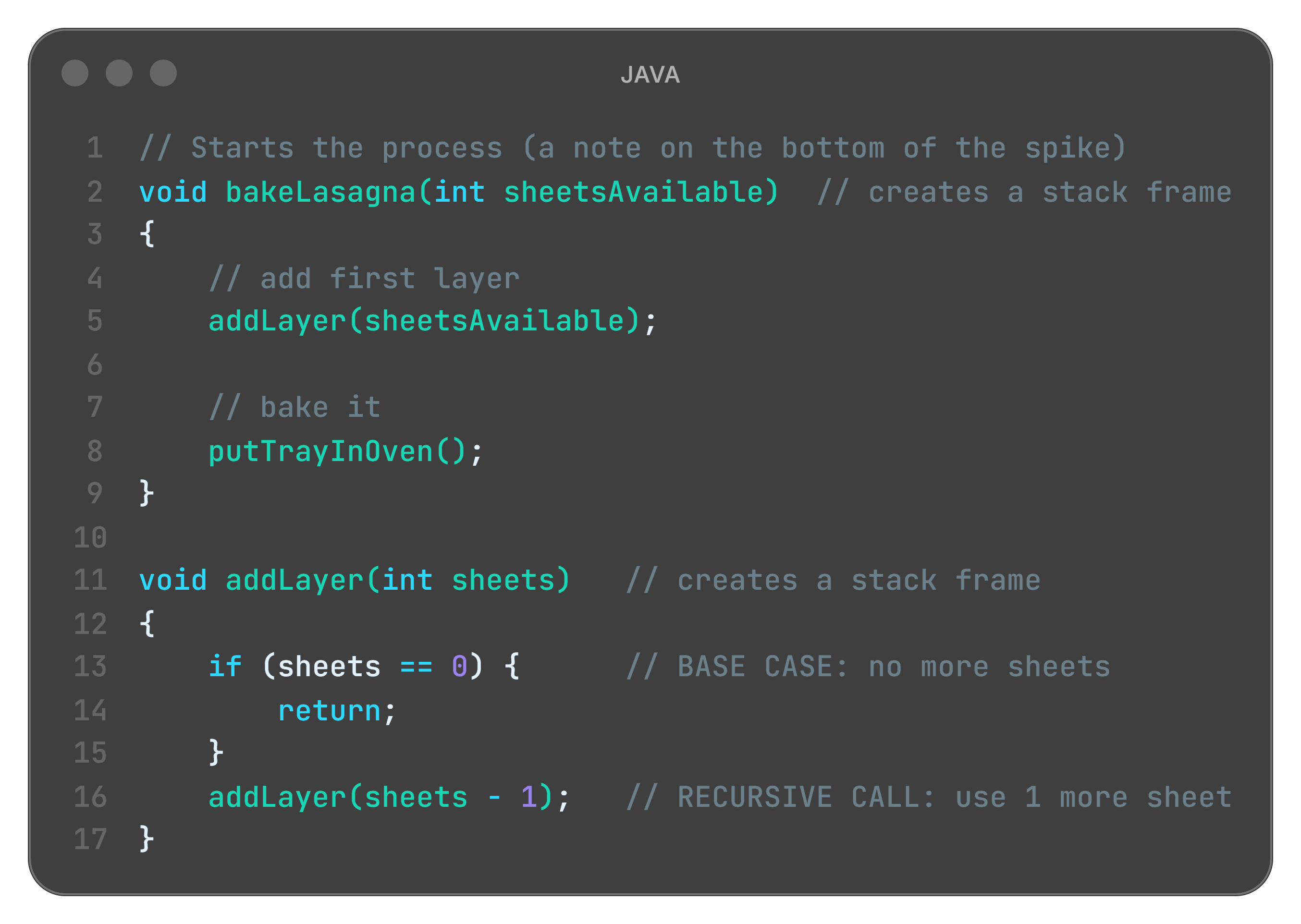
What is happening here?
bakeLasagna is the first ticket: It sits at the very bottom of the spike. It is the main() function that stays in memory and “holds” the entire operation together until everything else completes.
every addLayer is a new ticket: Each time the function calls itself, a new ticket is poked onto the top of the spike (PUSH operation). And basically to rip it off (function to return) you must finish all others above it first.
the Base Case (sheets == 0): When there are no lasagna sheets left (ingredients exhausted), no new ticket is added, no new stack frame. Instead, the function returns immediately and the current ticket is ripped off.
unwinding the Stack: Julia (our CPU) then starts finishing the tasks, removing the tickets one by one from top to bottom (POP operation). She can only get back to the original bakeLasagna ticket once every single layer above it has been cleared.
The fact that the recursion code creates new frame for every recursive call is dangerous! If recursion goes too deep, you run out of room on the spike. No more tickets = kitchen explosion.
That's why every programming language sets hard limits on recursion depth to prevent consuming all stack memory and crashing the system:
Java - Dynamic limit (usually 1,000-10,000 calls) based on the
-Xssthread stack size setting. ThrowsStackOverflowError.Python - Typically 1,000 calls. Python is conservative. Throws
RecursionError. Check it withsys.getrecursionlimit().C# - Dynamic limit based on thread stack size (usually 1MB on 64-bit). Throws
StackOverflowException.
But how big is the Stack actually? The Stack size is set when the thread is created and doesn’t grow dynamically. Think of it like Julia’s spike - once manufactured, that’s its max height. Typical defaults:
Java - 1MB per thread (configurable via
-Xss1m)Python - ~8MB on most systems
C#/.NET - 1MB (64-bit), 256KB (32-bit)
Go - Starts tiny (2KB), grows up to 1GB
Each Stack Frame eats a slice of that memory. A simple function? Maybe 50-100 bytes. A function with large local arrays? Could be several KB.
That’s why deep recursion with heavy local variables is a double threat! You’re both adding tickets AND making each ticket thicker.
Hit the limit? Your program crashes with an error instead of taking down the entire system. Better a controlled explosion than burning down the whole restaurant.
B. The Iterative Approach (Single Frame Efficiency)
If we change the implementation with an iterative approach, instead of poking many tickets (frames) onto the spike, Julia uses one single ticket and just updates the numbers on it until she's done. The same way a while loop normally creates a single stack frame and it simply updates the values (the state) inside that same memory space over and over.

As the code shows, you are not calling a function inside the loop, therefore, no new stack frames are created. This makes the iterative approach significantly more memory-efficient.
So, should you ditch recursion for a while loop every time?
Absolutely not!
First: Recursion is your best ‘chef’s knife’ for traversing hierarchical structures like a nested file system or organization chart. It’s simply cleaner to implement.
Second: While loop by itself doesn’t keep you safe. A poorly defined stop condition is equally disastrous for both recursion and a while loop. You won’t overflow the stack this time, but you’ll certainly serve up a Lasagna Infinita - the dreaded infinite loop.
What happens with infinite loop?
We have a single Stack Frame and on each iteration Julia is furiously erasing and rewriting the last line on the same piece of paper. With a bad Base Case, the tickets count on the spike stays the same (Thank Lord!), so the Stack remains in perfect shape.
Your Memory (the Heap) will also be fine, unless within the loop we start piling up massive objects. It’s like if Julia, instead of just erasing and rewriting lines on the small ticket, decides to turn it to a bible-sized novel.
Your CPU, however, will be sizzling at 100% like Julia’s pan, trapped in endless loop of repeating an operation. It’s the perfect recipe for a system freeze.
Quick tips:
🔧 Production Pattern: Set your JVM stack size explicitly with ‘-Xss2m’ (doubles default from 1MB to 2MB). Don’t wait for Stack Overflow in proction-test your deepest recursion paths with n=10,000 in staging first.
💼 Business Decision Alert: Recursion isn’t “elegant code for developers to enjoy.” It’s a production risk that needs depth limits, monitoring, and fallback. When reviewing architecture, ask: “What’s our recursion ceiling and what happens when we hit it?”
Famous Failures
Real systems. Real crashes. Real lessons:
Apple Image I/O (2021/2022): The “Infinity Image” Stack Overflow
Simply previewing a malicious image could crash your iPhone. No click required.
Apple's Image I/O framework parsed image metadata using recursive calls, one function call per nested layer. Attackers embedded hundreds of layers deep into image files. When iOS tried to render the thumbnail, the parser recursively descended through every layer with no depth limit. Result: Stack Overflow at layer 800+, instant device crash. The vulnerability was exploitable via Safari preview or even iMessage, just receiving the image was enough.
Lesson learned: Even "read-only" operations like image parsing are dangerous when using unbounded recursion on untrusted input.
Read more: Project Zero: ForcedEntry - NSO Group’s iMessage Zero-Click Exploit
Node.js & JSON Parsers (2014-present): The “Nested Doll” Attack
Send a JSON file with 10,000 nested brackets. Watch the server explode.
Most JSON/XML parsers use recursion to navigate nested structures - one Stack Frame per bracket level. Node.js v0.8-v0.10 had no depth limits. Attackers sent payloads like [[[[...]]]] with thousands of levels. Each bracket triggered a recursive call, stacking frames until overflow. Google’s Gson library had the same flaw pre-2023. Result: instant server crash, perfect DoS vector. The pattern keeps reappearing across different parsers because recursive descent is the “elegant” solution... until poduction.
Lesson learned: Never trust user input. Always enforce max depth limits in recursive parsers (typical safe limit: 100-200 levels).
Read more: Node.js V8 Memory Corruption Vulnerability
Quick tips:
👨💼 For Your Next Board Meeting: “Remember the Apple crash? One malicious image = device down. That's Stack Overflow. Our code needs the same protection - depth limits on every recursive path.”
👨🎓 Teaching Moment: Pull up Julia's kitchen. Walk through: "See the spike? That's our Stack. Each lasagna layer = recursive call. Hit the ceiling? Stack Overflow. Base Case = the brake.”
Key Takeways
The CEO-Digestible Recipe
When the CTO says “stack overflow from unbounded recursion”, translate it like this:
♨ STACK - Order spike next to the stove. Poke ticket on top, tear off when done. Fast but limited height.
♨ HEAP - Warehouse down the corridor. Tons of space, but you walk there (slower access).
♨ STACK FRAME - Single ticket on spike. Created when function called, destroyed when it returns.
♨ LIFO (Last-In, First-Out) - Always process topmost ticket first. Perfect for nested function calls.
♨ BASE CASE - Stop condition in recursion. Like bottom of lasagna tray - time to stop adding layers.
♨ RECURSION - Each step creates new ticket on spike. Elegant but dangerous if too deep.
♨ ITERATION (While Loop) - One ticket, rewrite it over and over. Memory-efficient, but bad stop condition = infinite loop.
♨ STACK OVERFLOW - When spike hits ceiling. Too many nested calls = no more room = kitchen explodes.
♨ THREAD SAFETY - Every chef gets private spike. Chef A never touches Chef B’s tickets - why local variables are thread-safe.
The Three Rules of Recursion (Remember These)
1. If you can’t guarantee a base case, don’t use recursion.
No stop condition = infinite layers = kitchen explosion. Test with n=10,000 before production.
2. Depth limits are platform-dependent, not optional.
Java: 1,000-10,000 calls. Python: 1,000 calls. C#: 1MB stack. Know your limits.
3. Iteration is safer for user-controlled input.
Apple’s malicious image had 800+ nested layers. One bad input shouldn’t crash production.
For Engineers: Stack Overflow Detection Patterns
Watch for these patterns in production:
Pattern 1: The Nested Bomb
Symptom: StackOverflowError with no obvious infinite recursion in code
Diagnosis: Deep but finite recursion on untrusted input (Apple image parser: 800 layers)
Fix: Add max depth counter, throw exception at limit (typical safe limit: 100-200)
Pattern 2: The Missing Base Case
Symptom: Stack trace shows same function repeated thousands of times
Diagnosis: Base case never reached or incorrectly implemented
Fix: Add unit tests with edge cases (n=0, n=1, n=10000), verify base case always hits
Pattern 3: The Heavy Frame
Symptom: Stack overflow at surprisingly low depth (50-100 calls instead of 1,000+)
Diagnosis: Large local variables in recursive function (arrays, buffers)
Fix: Move large allocations to heap, or switch to iteration with single allocation
Metrics to monitor:
Stack depth in recursive functions (instrument entry/exit)
Max recursion depth seen in production (track histogram)
StackOverflowError rate (should be zero in production)
Thread stack size configuration (default vs custom)
For Tech Leads: Design Review Questions
Before approving any recursive code, require answers to:
1. What’s the base case and is it guaranteed to hit?
“When n reaches 0” isn’t enough. Prove it terminates for all valid inputs.
2. What’s the maximum recursion depth for worst-case input?
“Shouldn’t be too deep” is not acceptable. Need concrete number or proof it’s bounded.
3. Does this handle user-controlled input?
User input → iteration preferred. Internal traversal → recursion acceptable.
4. What happens at the platform recursion limit?
Graceful error or crash? Catch StackOverflowError (.NET allows it, Java doesn’t).
5. Did we test with n=10,000?
If test passes, you’re safe on most platforms. If it fails, redesign or set explicit limit.
Team Practice: Quarterly “Recursion Failure Drills”
Simulate:
Malicious input with 10,000 nested levels
Base case that never triggers (off-by-one error)
Heavy local variables causing early overflow
Measure: Does it crash gracefully or take down the process?
For Managers: Investment Priorities
What stack overflow looks like in business terms:
Apple iOS (2021): Malicious images crashed devices via preview. No click needed. Vulnerability in recursive image parser.
Node.js (2014): Deeply nested JSON crashed servers. DoS attack vector via recursive parser without depth limits.
Common pattern: Recursive code + untrusted input = production vulnerability.
Questions to ask your CTO:
Where do we use recursion in production code?
Do we enforce depth limits on recursive functions?
How do we handle user-controlled nested data (JSON, XML, images)?
What’s our testing strategy for deep recursion scenarios?
When was the last StackOverflowError in production?
Budget Allocation:
Invest in recursion safety:
Static analysis tools - Detect unbounded recursion in code review
Depth limiting libraries - Enforce max depth across services
Fuzzing infrastructure - Test with extreme inputs (n=100,000)
Developer training - Recursion vs iteration decision framework
The decision: Apple crashed devices in production. Node.js enabled DoS attacks. Prevention is cheaper than incident response.
Bonus content: download the episode comic:
Perfect for: Presentations, onboarding docs, tech talks
Using it? Reply and tell me!
Closing Time
Cody, the bartender: “Ollie is still cleaning up the mess in the kitchen, while Julia is already rewriting the ‘logic’ for tomorrow’s service.
But let’s see how things will play out next time. Our boss Nina Glamour is preparing the restaurant for the Grand Opening, but eventually she will learn the hard way that LIFO stack, while perfect for program code execution, does not fit for everything…
Get ready for Episode 2 and remember! Always be careful with your Base Case!
Cheers.”
Episode 2 Drops in Two Weeks
When VIP Orders Starve: LIFO vs FIFO.
Jack Falcone is NOT happy. His order's been sitting at the bottom while newer tickets get processed first.
But Nina Glamour's Grand Opening depends on keeping VIPs happy. When does LIFO work? When should you use FIFO? And when will both strategies fail you spectacularly?
What is already served from Season 01 menu?





Feedback?
What worked for you? What didn’t? What would you like to see more of?
Share your thoughts in the comments below 👇
Know someone who needs to explain Stack Overflow? Someone preparing a tech talk? A junior confused about recursion?
Illustration credits: Comic scenes conceptualized by 8bytes! and rendered by Nano Banana.
Hello, Sous-Chefs! What section was most valuable to you? Am I missing something, you would like to read in my deep dives? Please, feel free to comment and help me polish my future content!